Table of Contents
The General Transit Feed Specification (GTFS) defines a common format for public transportation schedules and associated geographic information. GTFS-realtime is used to specify real-time transit data. Many transportation agencies around the world publish their data in GTFS and GTFS-realtime format and make them publicly available. A well-known repository containing such data is OpenMobilityData.
In this chapter, we illustrate how to load GTFS data in MobilityDB. For this, we first need to import the GTFS data into PostgreSQL and then transform this data so that it can be loaded into MobilityDB. The data used in this tutorial is obtained from STIB-MIVB, the Brussels public transportation company and is available as a ZIP file. You must be aware that GTFS data is typically of big size. In order to reduce the size of the dataset, this file only contains schedules for one week and five transportation lines, whereas typical GTFS data published by STIB-MIVB contains schedules for one month and 99 transportation lines. In the reduced dataset used in this tutorial the final table containing the GTFS data in MobilityDB format has almost 10,000 trips and its size is 241 MB. Furtheremore, we need several temporary tables to transform GTFS format into MobilityDB and these tables are also big, the largest one has almost 6 million rows and its size is 621 MB.
Several tools can be used to import GTFS data into PostgreSQL. For example, one publicly available in Github can be found here. These tools load GTFS data into PostgreSQL tables, allowing one to perform multiple imports of data provided by the same agency covering different time frames, perform various complex tasks including data validation, and take into account variations of the format provided by different agencies, updates of route information among multiple imports, etc. For the purpose of this tutorial we do a simple import and transformation using only SQL. This is enough for loading the data set we are using but a much more robust solution should be used in an operational environment, if only for coping with the considerable size of typical GTFS data, which would require parallelization of this task.
The ZIP file with the data for this tutorial contains a set of CSV files (with extension .txt) as follows:
-
agency.txtcontains the description of the transportation agencies provinding the services (a single one in our case). -
calendar.txtcontains service patterns that operate recurrently such as, for example, every weekday. -
calendar_dates.txtdefine exceptions to the default service patterns defined incalendar.txt. There are two types of exceptions: 1 means that the service has been added for the specified date, and 2 means that the service has been removed for the specified date. -
route_types.txtcontains transportation types used on routes, such as bus, metro, tramway, etc. -
routes.txtcontains transit routes. A route is a group of trips that are displayed to riders as a single service. -
shapes.txtcontains the vehicle travel paths, which are used to generate the corresponding geometry. -
stop_times.txtcontains times at which a vehicle arrives at and departs from stops for each trip. -
translations.txtcontains the translation of the route information in French and Dutch. This file is not used in this tutorial. -
trips.txtcontains trips for each route. A trip is a sequence of two or more stops that occur during a specific time period.
We decompress the file with the data into a directory. This can be done using the command.
unzip gtfs_data.zip
We suppose in the following that the directory used is as follows /home/gtfs_tutorial/.
We create the tables to be loaded with the data in the CSV files as follows.
CREATE TABLE agency (
agency_id text DEFAULT '',
agency_name text DEFAULT NULL,
agency_url text DEFAULT NULL,
agency_timezone text DEFAULT NULL,
agency_lang text DEFAULT NULL,
agency_phone text DEFAULT NULL,
CONSTRAINT agency_pkey PRIMARY KEY (agency_id)
);
CREATE TABLE calendar (
service_id text,
monday int NOT NULL,
tuesday int NOT NULL,
wednesday int NOT NULL,
thursday int NOT NULL,
friday int NOT NULL,
saturday int NOT NULL,
sunday int NOT NULL,
start_date date NOT NULL,
end_date date NOT NULL,
CONSTRAINT calendar_pkey PRIMARY KEY (service_id)
);
CREATE INDEX calendar_service_id ON calendar (service_id);
CREATE TABLE exception_types (
exception_type int PRIMARY KEY,
description text
);
CREATE TABLE calendar_dates (
service_id text,
date date NOT NULL,
exception_type int REFERENCES exception_types(exception_type)
);
CREATE INDEX calendar_dates_dateidx ON calendar_dates (date);
CREATE TABLE route_types (
route_type int PRIMARY KEY,
description text
);
CREATE TABLE routes (
route_id text,
route_short_name text DEFAULT '',
route_long_name text DEFAULT '',
route_desc text DEFAULT '',
route_type int REFERENCES route_types(route_type),
route_url text,
route_color text,
route_text_color text,
CONSTRAINT routes_pkey PRIMARY KEY (route_id)
);
CREATE TABLE shapes (
shape_id text NOT NULL,
shape_pt_lat double precision NOT NULL,
shape_pt_lon double precision NOT NULL,
shape_pt_sequence int NOT NULL
);
CREATE INDEX shapes_shape_key ON shapes (shape_id);
-- Create a table to store the shape geometries
CREATE TABLE shape_geoms (
shape_id text NOT NULL,
shape_geom geometry('LINESTRING', 4326),
CONSTRAINT shape_geom_pkey PRIMARY KEY (shape_id)
);
CREATE INDEX shape_geoms_key ON shapes (shape_id);
CREATE TABLE location_types (
location_type int PRIMARY KEY,
description text
);
CREATE TABLE stops (
stop_id text,
stop_code text,
stop_name text DEFAULT NULL,
stop_desc text DEFAULT NULL,
stop_lat double precision,
stop_lon double precision,
zone_id text,
stop_url text,
location_type integer REFERENCES location_types(location_type),
parent_station integer,
stop_geom geometry('POINT', 4326),
platform_code text DEFAULT NULL,
CONSTRAINT stops_pkey PRIMARY KEY (stop_id)
);
CREATE TABLE pickup_dropoff_types (
type_id int PRIMARY KEY,
description text
);
CREATE TABLE stop_times (
trip_id text NOT NULL,
-- Check that casting to time interval works.
arrival_time interval CHECK (arrival_time::interval = arrival_time::interval),
departure_time interval CHECK (departure_time::interval = departure_time::interval),
stop_id text,
stop_sequence int NOT NULL,
pickup_type int REFERENCES pickup_dropoff_types(type_id),
drop_off_type int REFERENCES pickup_dropoff_types(type_id),
CONSTRAINT stop_times_pkey PRIMARY KEY (trip_id, stop_sequence)
);
CREATE INDEX stop_times_key ON stop_times (trip_id, stop_id);
CREATE INDEX arr_time_index ON stop_times (arrival_time);
CREATE INDEX dep_time_index ON stop_times (departure_time);
CREATE TABLE trips (
route_id text NOT NULL,
service_id text NOT NULL,
trip_id text NOT NULL,
trip_headsign text,
direction_id int,
block_id text,
shape_id text,
CONSTRAINT trips_pkey PRIMARY KEY (trip_id)
);
CREATE INDEX trips_trip_id ON trips (trip_id);
INSERT INTO exception_types (exception_type, description) VALUES
(1, 'service has been added'),
(2, 'service has been removed');
INSERT INTO location_types(location_type, description) VALUES
(0,'stop'),
(1,'station'),
(2,'station entrance');
INSERT INTO pickup_dropoff_types (type_id, description) VALUES
(0,'Regularly Scheduled'),
(1,'Not available'),
(2,'Phone arrangement only'),
(3,'Driver arrangement only');
We created one table for each CSV file. In addition, we created a table shape_geoms in order to assemble all segments composing a route into a single geometry and auxiliary tables exception_types, location_types, and pickup_dropoff_types containing acceptable values for some columns in the CSV files.
We can load the CSV files into the corresponding tables as follows.
COPY calendar(service_id,monday,tuesday,wednesday,thursday,friday,saturday,sunday, start_date,end_date) FROM '/home/gtfs_tutorial/calendar.txt' DELIMITER ',' CSV HEADER; COPY calendar_dates(service_id,date,exception_type) FROM '/home/gtfs_tutorial/calendar_dates.txt' DELIMITER ',' CSV HEADER; COPY stop_times(trip_id,arrival_time,departure_time,stop_id,stop_sequence, pickup_type,drop_off_type) FROM '/home/gtfs_tutorial/stop_times.txt' DELIMITER ',' CSV HEADER; COPY trips(route_id,service_id,trip_id,trip_headsign,direction_id,block_id,shape_id) FROM '/home/gtfs_tutorial/trips.txt' DELIMITER ',' CSV HEADER; COPY agency(agency_id,agency_name,agency_url,agency_timezone,agency_lang,agency_phone) FROM '/home/gtfs_tutorial/agency.txt' DELIMITER ',' CSV HEADER; COPY route_types(route_type,description) FROM '/home/gtfs_tutorial/route_types.txt' DELIMITER ',' CSV HEADER; COPY routes(route_id,route_short_name,route_long_name,route_desc,route_type,route_url, route_color,route_text_color) FROM '/home/gtfs_tutorial/routes.txt' DELIMITER ',' CSV HEADER; COPY shapes(shape_id,shape_pt_lat,shape_pt_lon,shape_pt_sequence) FROM '/home/gtfs_tutorial/shapes.txt' DELIMITER ',' CSV HEADER; COPY stops(stop_id,stop_code,stop_name,stop_desc,stop_lat,stop_lon,zone_id,stop_url, location_type,parent_station) FROM '/home/gtfs_tutorial/stops.txt' DELIMITER ',' CSV HEADER;
Finally, we create the geometries for routes and stops as follows.
INSERT INTO shape_geoms SELECT shape_id, ST_MakeLine(array_agg( ST_SetSRID(ST_MakePoint(shape_pt_lon, shape_pt_lat),4326) ORDER BY shape_pt_sequence)) FROM shapes GROUP BY shape_id; UPDATE stops SET stop_geom = ST_SetSRID(ST_MakePoint(stop_lon, stop_lat),4326);
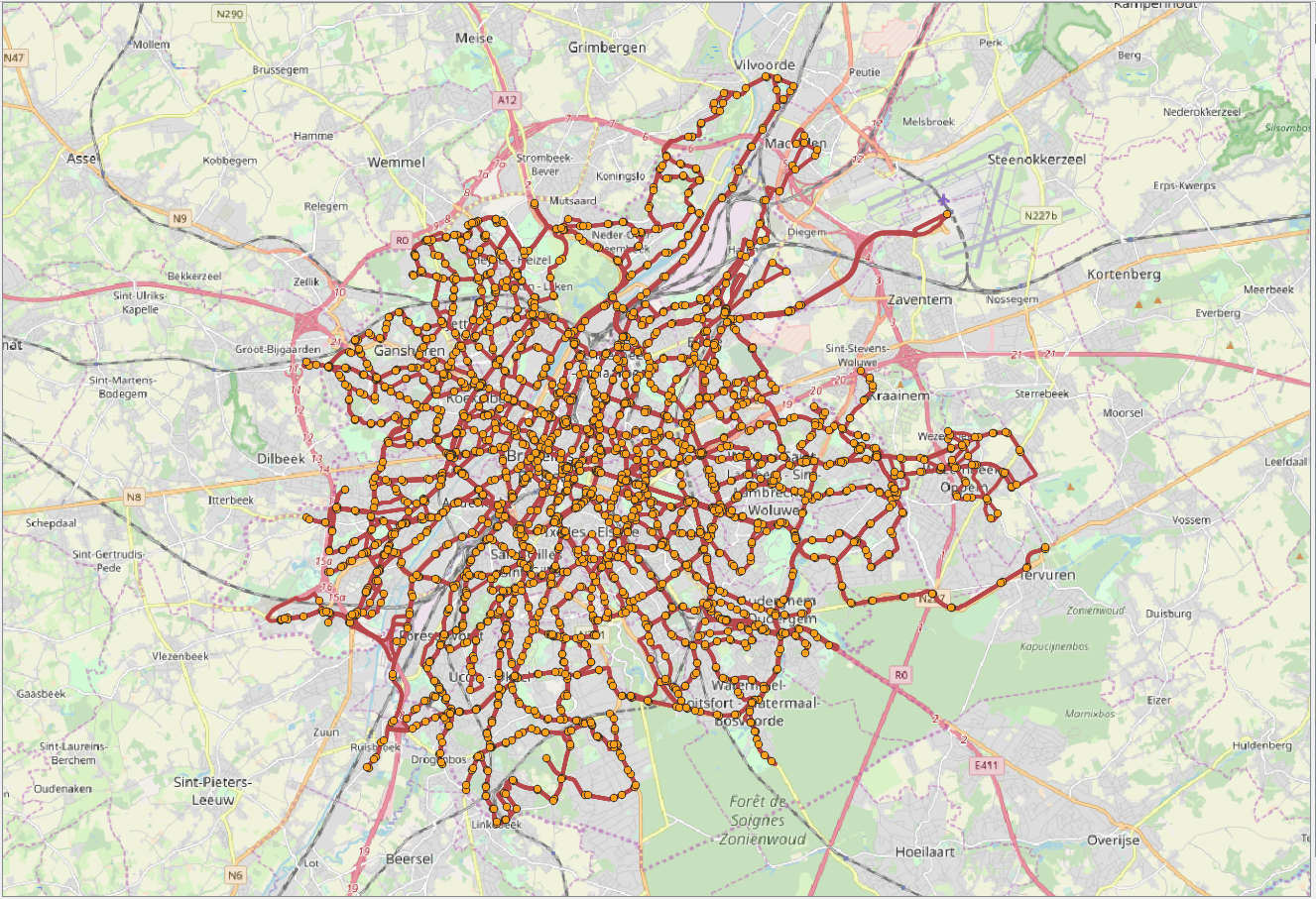
The visualization of the routes and stops in QGIS is given in Figure 4.1, “Visualization of the routes and stops for the GTFS data from Brussels.”. In the figure, red lines correspond to the trajectories of vehicles, while orange points correspond to the location of stops.